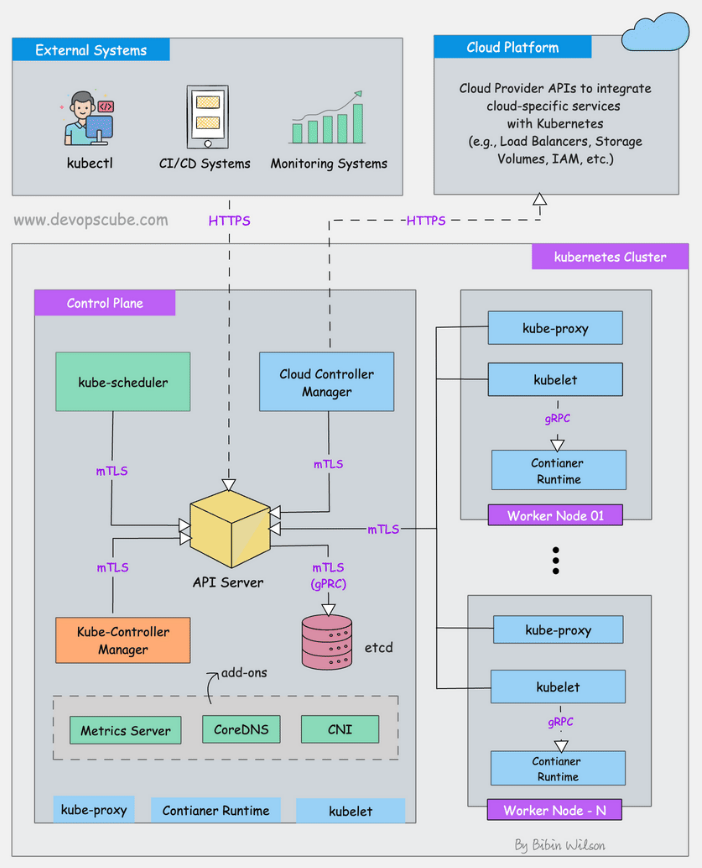
Le kube-scheduler est responsable de la planification des pods sur les nœuds de travail dans un cluster Kubernetes. Dès qu’un nouveau pod est créé, il vérifie ses besoins (CPU, mémoire, affinité, tolérances, priorités, volumes persistants, etc.) et choisit le nœud le plus adapté.
Principes de fonctionnement du scheduler
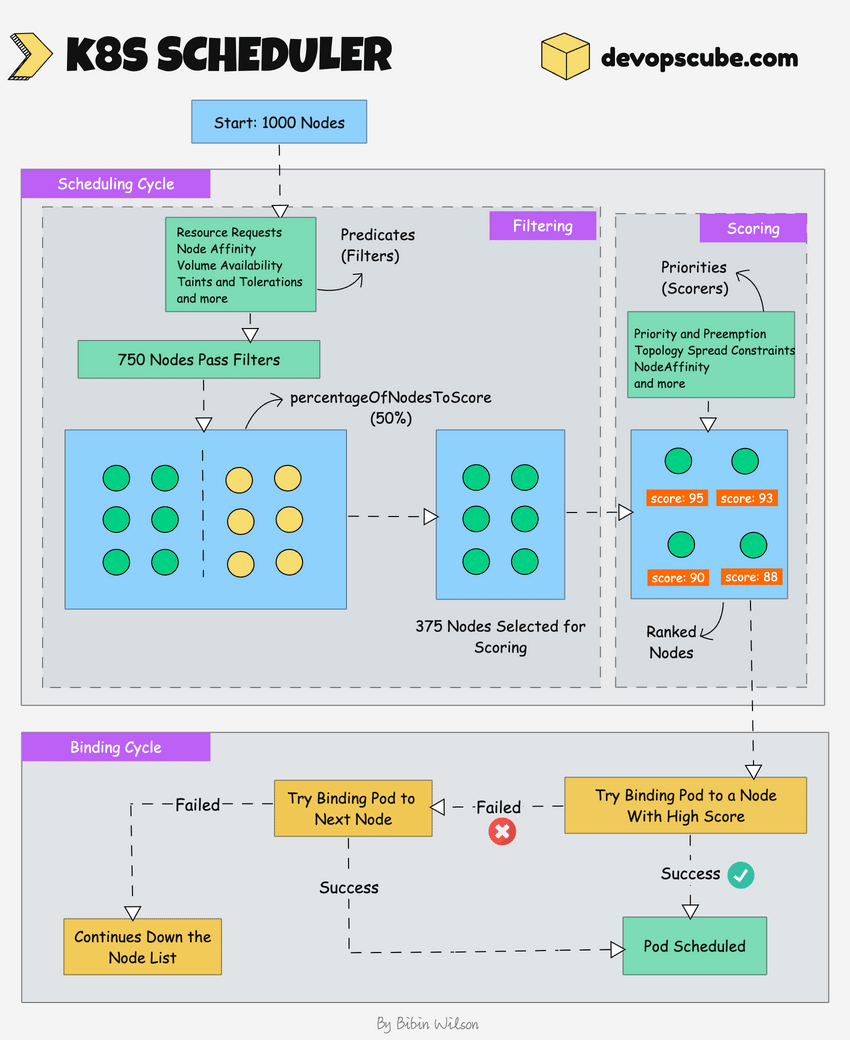
| Étape | Description |
|---|---|
| Écoute des événements | Le scheduler surveille l’API server à la recherche de pods à planifier. |
| Cycle de planification | Comprend deux phases : filtrage des nœuds (nodes éligibles) et scorage (classement). |
| Filtrage (Filtering) | Élimine les nœuds qui ne conviennent pas (pas assez de ressources, contraintes non respectées, etc.). N’utilise pas forcément tous les nœuds : la valeur par défaut pour le paramètre percentageOfNodesToScore est 50% (5% dans les très grands clusters), pour optimiser les performances. |
| Scorage (Scoring) | Attribue un score à chaque nœud restant via différents plugins ou fonctions : celui avec le score le plus élevé est sélectionné. Si égalité, sélection aléatoire. |
| Binding (liaison) | Une fois le nœud choisi, le scheduler informe l’API server pour lier le pod au nœud concerné (événement de “binding”). |
Fonctionnalités clés et options avancées
| Fonctionnalité | Détail |
|---|---|
| Priorité | Les pods avec la priorité la plus haute sont planifiés en premier ; possibilité d’éviction/migration de pods si nécessaire. Voir PriorityClass. |
| Schedulers personnalisés | Possibilité de déployer plusieurs schedulers personnalisés en parallèle du scheduler natif. Un pod peut utiliser un scheduler spécifique déclaré dans son manifeste de déploiement. |
| Cadre extensible (Framework) | Le scheduler propose un framework modulaire : on peut y ajouter des plugins de scheduling personnalisés pour étendre ses fonctionnalités (filtrage, scorage, binding, etc.). |
| Gestion des gros clusters | Utilisation de l’option percentageOfNodesToScore pour limiter le nombre de nœuds évalués et gagner en efficacité sur des clusters volumineux. |
| Surveillance des pods | Après la planification, certains pods peuvent être déplacés ou évincés selon les besoins du cluster ou les changements de priorité. |
Résumé de l’algorithme de planification
1. Détection d'un pod non planifié par le scheduler.
2. Phase de filtrage : sélection des nœuds répondant aux exigences du pod.
3. Phase de scorage : classement des nœuds restants via des plugins/scoring functions.
4. Sélection du meilleur nœud (ou aléatoirement en cas d'égalité).
5. Événement de binding envoyé à l'API server pour lier le pod au nœud.
Tableau synthétique
| Fonction/Phase | Explication |
|---|---|
| Surveillance | Observe l’API server : détecte les pods à planifier. |
| Filtrage | Écarte les nœuds ne convenant pas (ressources, affinités, tolérances, etc.). |
| Scorage | Attribue un score à chaque nœud restant (plugins, règles). |
| Binding | Associe le pod au nœud le mieux noté. |
| Priorité des pods | Les pods prioritaires sont planifiés en premier ; gestion d’éviction si nécessaire. |
| Scheduling context | Ensemble cycle de scheduling (sélection du nœud) + cycle de binding (application de la décision). |
| Schedulers multiples et plugins | Prise en charge de schedulers personnalisés et de plugins pour filtrer/classer selon des règles spécifiques. |
Dans un déploiement Nginx
- Détecte le pod Nginx nouvellement créé (sans nœud assigné).
- Analyse les ressources disponibles sur chaque worker (CPU, affinités, taints/tolerations…).
- Sélectionne le nœud le plus adapté et émet un “bind” via l’API server.